Last Resor(d)le
This is a script written by Pat Devlin to help solve the popular wordle puzzle. Simply enter each word that you’ve guessed so far into the text box. Select the revealed color of each letter by clicking on the corresponding square. See below for more.
Output
Number of solutions:Suggested Guesses:
Random guess:BestEntropy guess:
BestMax guess:
BestAverage guess:
List of possible answers:
*To avoid spoilers, you can select that the output of the function be hidden. If so, individual pieces of output can then be revealed or hidden by clicking on their corresponding text.
About
What can this site do?
- Solve wordle puzzles: After submitting your puzzle, the site gives next guesses as suggested by four different algorithms.
- Solve "more"-dle puzzles: For more-dle puzzles (dordle, quordle, ...), the 'clear colors' feature is especially helpful. The sedecordle can very often be solved by starting with the guesses 'train' and 'close' and then repeatedly identifying a word that has only one possible option (thus finding all 16 words using only 18 guesses).
- Solve absurdle puzzles: Click "Solve wordle!" without providing any input to get a suggested starting word. Enter the suggested word into absurdle and use the response back here to get the next suggested word. Because absurdle is adversarial, the BestMax algorithm suggestion is well-suited for this.
- Play wordle against you: You think of a five-letter word and run this in the same way you would run absurdle
- Toggle spoilers: To avoid spoilers, you can select that the output of the function be hidden. If so, individual pieces of output can then be revealed or hidden by clicking on their corresponding text.
- Puzzle mode: Clicking the Random Input button generates a wordle puzzle with several guesses already made. You can either use this to demo the site or [by hiding spoilers] you can use it to practice your wordle skills!
Maybe you want to know...
- Why can't it find my word?
- First make sure you're entering it correctly. For instance, if the answer is BAKER and we guess ARROW, then the second R should not be colored yellow.
- If you're entering it correctly, then it's likely that the word isn't in the original wordle dictionary (this happens surprisingly often. Some sites like squardle take their answers from a dictionary with a lot more words).
- In particular, the wordle answer dictionary is missing a lot of five-letter words that end in S. For instance, it's missing FINDS, HELPS, BOOKS.
- Which guess should I use?
- The site runs four different algorithms to suggest which word to play next. All of these algorithms are running in "hard mode" which means that each new guess must actually be a plausible answer consistent with all the information we have so far.
- The random guess is silly. You shouldn't use that unless you're having fun.
- Each of the other guesses is the result of careful thinking. Often they agree, but if not, the BestEntropy guess is often slightly better.
Performance of algorithms
This site has three simple algorithms to solve the wordle in hard mode. Running each of these algorithms for all possible wordle answers gives us the following distribution for the number of guesses needed.
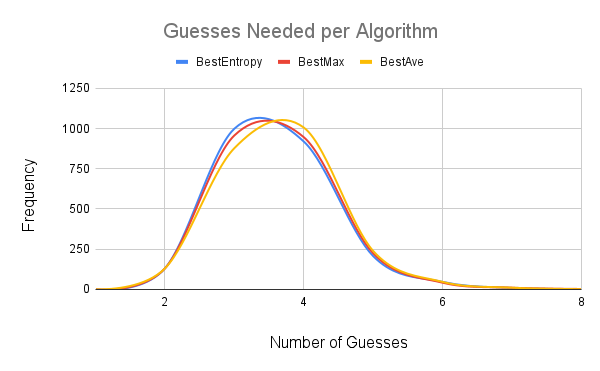
Here, the algorithms have almost identical distributions with the largest difference being that BestEntropy does a better job at guessing the word in 3 guesses (especially relative to BestAve). The best of these algorithms is BestEntropy (requiring 3.60 guesses on average) followed by BestMax (averaging 3.62 guesses), and the worst is BestAve (averaging 3.67 guesses). Each of these simple algorithms guesses the word within 6 tries with the following exceptions:
| BestEntropy | BestMax | BestAve | |
| pound | 4 | 4 | 7 |
| water | 4 | 7 | 7 |
| winch | 5 | 7 | 5 |
| shave | 5 | 7 | 7 |
| wound | 5 | 7 | 8 |
| wight | 7 | 5 | 7 |
| foyer | 7 | 7 | 7 |
| graze | 7 | 7 | 7 |
| match | 7 | 7 | 7 |
| swore | 7 | 7 | 7 |
| tatty | 7 | 7 | 7 |
| waste | 7 | 7 | 7 |
| willy | 7 | 7 | 7 |
| goner | 8 | 8 | 8 |
| watch | 8 | 8 | 8 |
How does this all work?
(Description below is about to get more technical for those who care)Big picture
This site (statically hosted by github) was built simply by writing its index file in html, css, and javascript. The key functionality is to make an API call that invokes an AWS lambda instance that I set up. This API call passes the board (with colors) as input to a python script that I wrote, and it receives a handful of outputs which are used to populate the page.The repo for the stand-alone python code is available here (for the lambda function, naturally I had to add a script that handles the API request, but this was done in exactly the way you're imagining). To handle scaling [and out of fear of paying AWS some extra pennies in hosting fees], I also slightly optimized the python code for the lambda function by speeding up all calls by roughly a multiplicative factor of 10. Memory allocation per call is minimal, so no additional effort was made to optimize that.
Algorithms
The back-end is written in python, which was honestly just chosen for the sake of variety. Another choice for a project like this could have been C or C++, especially since it's relatively easy to imagine writing many simple procedures, which we'll want to call many times (for instance, if we wanted to explore the exponential-size min-max decision tree for this problem). Although a low-level compiled language would ultimately end up being substantially faster, I figured I'd do this one in python because I had just finished another project in C++.The Random algorithm just outputs a random word consistent with the guesses thus far. Each of the other three algorithms does the following (as described using the language of set theory):
- Load the wordle dictionary
- Find all words consistent with what we know thus far
- For each possible next guess, we consider how that guess might be colored:
- This partitions the set of consistent words into equivalence classes, where two words are in the same class iff they would give our potential guess the same color.
- [From an information-theoretic point of view, words in the same equivalence class would therefore be indistinguishable from each other given the guesses we've made thus far]
- (In the code, the equivalence classes of this relation are called word classes)
- Give this potential guess some "score," which is a function of the size of this partition.
- Propose the potential guess which has the best "score"
For example! Suppose we intially have no information, and we are considering guessing "jazzy". Then the following is true:
- there are 1111 possible answers where "jazzy" would be colored all gray
- there are 2 possible answers where "jazzy" would have its "j" yellow and all other colors gray
- there are 10 possible answers where "jazzy" would have its "j" green and all other colors gray
- there is 1 possible answer where "jazzy" would have its "j" green, the "a" yellow, and all other colors gray
- Et cetera...
Although we lose information by only considering this sequence of numbers (1111, 2, 10, 1, ...)---e.g., if we land among the 10 guesses where J is green, how easy it is to distinguish those?---heuristically, this sequence of numbers is likely pretty telling of how good a guess "jazzy" is, and we just need to decide how to linearly order such sequences so that we can pick a 'best' choice. There are a bunch of good options, but three especially natural ones are the following:
- BestEntropy:
- The score function here is a weighted sum of the logarithms of the terms in the sequence. Mathematically speaking, this is computing a quantity known as the "entropy" of the random variable of "what is the answer" conditioned on the random variable of "how will this potential guess be colored."
- This algorithm has the very elegant description "simply pick the word that minimizes the entropy."
- Entropy is the cornerstone of information theory, and it's the subject of my favorite research paper of all time (by a lot) [and also the most cited math/cs paper of all time (by a lot!)].
- Entropy is essentially "how many yes/no questions would you need to ask to determine the answer," and it is therefore an extremely natural choice. That said, notice that when we play wordle, we aren't asking yes/no questions (if we were, then minimizing entropy is literally the best you could hope to do). Instead! When we guess a word, there are way more than 2 possible outcomes: namely we see which letters get which colors, which is a lot more information than merely a yes/no question (and it's also hard to say how much "information" we'll be able to get out of subsequent guesses since it amounts to weird queries about the space or English words, which is itself really weird)
- BestMax:
- The score function here is just to take the maximum element of the sequence.
- This is an algorithm that greedily tries to avoid the worst-case scenario. That said, it only looks one step ahead, so it's just a first-level approximation of the optimal min-max algorithm.
- BestAve:
- The score function here is a weighted average of the terms of the sequence.
- You could say that it tries to minimize a sort of average of worst-case scenarios. Namely, it imagines it will get a response with probability proportional to each color class, but then it imagines naively testing each word in that color class one at a time.
- Equivalently, this algorithm picks the word such that an immediate random follow-up guess has the highest likelihood of working.
Analysis of algorithms
Each algorithm finds the next guess in time O(mn), where m is the number of possible words consistent with our information, and n is the set of words we're allowed to say. In hard mode, we have m=n, so this runs in order O(m^2) time. If we are given a dictionary and a set of previous guesses, we can find the set of words consistent with these guesses by just one pass through the dictionary*, so this procedure is done in linear time. As for space, each algorithm only needs O(1) memory.*There's an interesting question here about how this would scale for a dictionary of size N and a set of G guesses. Unfortunately, for us this point is purely moot since English uses an alphabet of constant size, and the words must be five letters long. Thus, the information in the guesses very quickly becomes redundant (e.g., we can only get at most 5 letters colored not-black, and a black letter conveys the same information regardless of where it appears in the word). In the general setting, I would conjecture that we could check N words against G different guesses in time O(N) + o(N*G) [thereby beating the trivial O(N*G) algorithm], but it would probably depend on what a "word" is...